
Providence
Przeprojektowana sieć Providentia.
Providentia Network to backend oparty na Django, który orkiestruje wielogałęziowe rozumowanie z wykorzystaniem modeli Google Gemini, natywnego koprocesora w C++ oraz opcjonalnych wizualizacji grafu myśli. Niniejszy dokument podsumowuje obecną architekturę i zawiera polecenia niezbędne do zbudowania i uruchomienia systemu lokalnie.
https://www.promptingguide.ai/techniques/tot
Yao et el. (2023) i Long (2023)
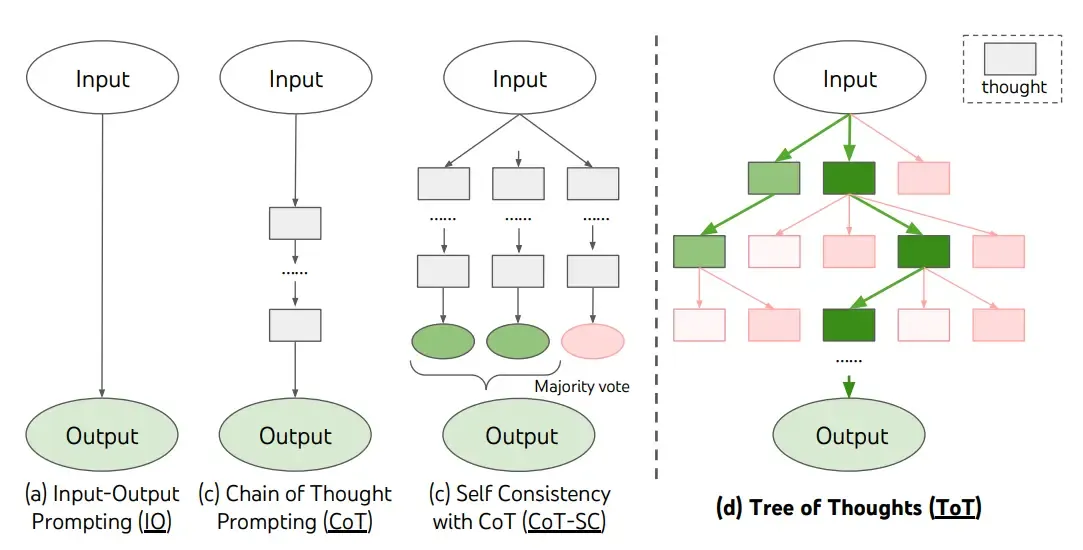
ostatnio zaproponowali Tree of Thoughts (ToT), framework uogólniający chain-of-thought prompting i zachęcający do eksploracji myśli, które służą jako pośrednie kroki w ogólnym rozwiązywaniu problemów z modelami językowymi.
ToT utrzymuje drzewo myśli, gdzie myśli reprezentują spójne sekwencje językowe służące jako pośrednie kroki w kierunku rozwiązania problemu. To podejście umożliwia modelowi językowemu samoocenę postępów poprzez pośrednie myśli zmierzające do rozwiązania problemu w ramach celowego procesu rozumowania. Zdolność modelu językowego do generowania i oceniania myśli jest następnie łączona z algorytmami przeszukiwania (np. przeszukiwanie wszerz i przeszukiwanie w głąb), aby umożliwić systematyczną eksplorację myśli z wyprzedzeniem i wycofywaniem.
Architektura systemu
Przepływ danych wysokiego poziomu
Klient -> /speech/simple_response (widok Django REST)
-> Python ThinkingManager (speech/context_manager/ThinkingManager.py)
-> Myśliciel C++ „Kievan Rus” (speech/context_manager/Kievan Rus/*.cpp)
-> API Gemini (JSON przez HTTPS)
-> Ładunek binarny (status + kontekst + podsumowanie)
-> Deserializator Python i rozwijanie gałęzi
-> Opcjonalny graf PNG (speech/context_manager/graphs/)
-> Odpowiedź tekstowa Django
Główne komponenty
Endpoint REST Django (
speech/views.py)
Przyjmuje prompt użytkownika, tworzy instancjęThinkingManageri przekazuje końcowy tekst instrukcji zwrócony przez agenta.Python Thinking Manager (
speech/context_manager/ThinkingManager.py)
Utrzymuje drzewo myśli i egzekwuje reguły architektoniczne:- Uruchamia natywny helper C++ jako podproces z bieżącą wiadomością, etykietą gałęzi i metadanymi iteracji.
- Parsuje odpowiedź binarną (1 bajt statusu, 4 bajty długości, ładunki UTF-8) i waliduje JSON względem
ContextStruct(Pydantic). - Rejestruje dla każdej gałęzi
probability_of_success, przyrostowypotential_score,possible_setbacksi etykiety gałęzi. - Gwarantuje co najmniej dwie eksploracje gałęzi na poziom i agreguje skumulowany wynik potencjału.
- Emituje tekstowe drzewo i opcjonalnie renderuje diagram PNG (patrz poniżej).
Myśliciel C++ „Kievan Rus” (
speech/context_manager/Kievan Rus/)
Zmodularyzowany na pliki nagłówkowe i źródłowe do parsowania argumentów, ładowania środowiska, wywołań HTTP Gemini (libcurl), konstrukcji promptów i serializacji binarnej.- Odczytuje klucz API Gemini ze środowiska procesu lub
.env. - Wykonuje dwa żądania Gemini: jedno do analizy strukturalnej, drugie do podsumowania narracyjnego.
- Koduje strukturalny kontekst i podsumowanie do przenośnego formatu binarnego konsumowanego przez Python.
- Główny cel Makefile
build-thinkerrekompiluje moduł (g++17,-lcurl) i jest automatycznie wywoływany podczas uruchamiania serwera.
- Odczytuje klucz API Gemini ze środowiska procesu lub
Renderowanie grafów (
plotting/graphing.py)
Używa Matplotlib (backend Agg) do wizualizacji końcowego drzewa myśli. Każdy węzeł zawiera etykietę gałęzi, zawinięty tekst planu, prawdopodobieństwa, przyrosty potencjału na krok, skumulowany potencjał oraz wyróżnienia dla stanów „końcowych” lub „żałowanych”. Obrazy trafiają dospeech/context_manager/graphs/.Agent Gemini (
speech/gemini/agent.py)
Lekka nakładka na klientagenaiGoogle. Moduł C++ odzwierciedla tę funkcjonalność dla rozumowania krytycznego pod względem opóźnień.
Semantyka rozgałęziania i punktacji
ThinkingManagerutrzymuje ograniczoną głębokość drzewa (max_iterations = 8), ale zapewnia, że każdy węzeł tworzy co najmniej dwie oznaczone gałęzie (np.Primary-A,Primary-B), chyba że ogranicza to limit iteracji.- Każda gałąź zawiera:
probability_of_success— liczba zmiennoprzecinkowa w zakresie[0.0, 1.0].potential_score— przyrost ze znakiem dodawany documulative_potential.possible_setbacks— tekstowa ocena ryzyka osadzona w logach, wyjściu konsoli i wizualizacjach.
- Logi są emitowane dla każdego utworzenia gałęzi, oceny numerycznej i kroku renderowania grafu w celu ułatwienia debugowania.
Konfiguracja i użycie
Wymagania wstępne
- Python 3 (zalecane jest środowisko virtualenv lub Conda).
g++z obsługą C++17 i nagłówkami deweloperskimi dla libcurl.- Dostęp do klucza API Gemini (
GEMINI_API_KEY) umieszczonego w.envlub w środowisku procesu. - (Opcjonalnie) Matplotlib do generowania grafów PNG; bez niego system loguje ostrzeżenie i pomija tworzenie wykresów.
Tworzenie środowiska
make update # używa environment.yml przez conda/micromamba
Nadpisywanie domyślnych ustawień:
make update CONDA_ENV=my-env-name
make update ENV_FILE=envs/dev.yml
make update CONDA=~/.local/bin/micromamba
Budowanie i uruchamianie
make run # rekompiluje myśliciela C++, a następnie uruchamia `python manage.py runserver`
Samodzielna kompilacja (jeśli potrzebna):
make build-thinker # cd speech/context_manager/Kievan\ Rus && g++ ... -lcurl
Serwer oczekuje pliku .env w katalogu głównym projektu, chyba że ustawiono KIEVAN_RUS_ENV_PATH.
Typowe cele Make
| Cel | Opis |
|---|---|
make run |
Buduje helper C++ i uruchamia serwer deweloperski Django |
make migrate |
Uruchamia migracje (makemigrations + migrate) |
make prepare |
Tworzy środowisko Conda z environment.yml |
make update |
Aktualizuje/tworzy środowisko Conda z przycinaniem |
make build-thinker |
Rekompiluje moduł rozumowania C++ |
make help |
Wyświetla dostępne cele (jeśli zdefiniowane w Makefile) |
Użyj PY=..., aby wskazać konkretny interpreter, lub nadpisz DJANGO_SETTINGS_MODULE według potrzeb.
Uwagi konfiguracyjne
.envGEMINI_API_KEY=twój-klucz # opcjonalne ustawienia Django...KIEVAN_RUS_ENV_PATH(zmienna środowiskowa) może nadpisać lokalizację.envdla procesu C++.Grafy są zapisywane do
speech/context_manager/graphs/thought_graph_<root-id>.png. Usuń katalog, aby wyczyścić artefakty.
Wskazówki dotyczące testowania i debugowania
- Protokół binarny jest ścisły; nieprawidłowo sformatowane odpowiedzi z Gemini (np. brakujące pola
text) zgłaszają jasne wyjątki logowane zarówno przez warstwę Python, jak i C++. - Tworzenie gałęzi, obliczanie prawdopodobieństwa i renderowanie grafów logują szczegółowy postęp z prefiksami
[ThinkingManager]. Obserwuj konsolę Django podczas rozwoju, aby śledzić przepływ rozumowania. - Jeśli brakuje Matplotlib, system kontynuuje działanie bez wyjścia PNG, ale loguje błąd importu.
Struktura repozytorium (wybrane)
speech/
├── context_manager/
│ ├── ThinkingManager.py # Orkiestrator Python
│ └── Kievan Rus/ # Natywny myśliciel C++ (zmodularyzowane źródła)
├── gemini/
│ └── agent.py # Nakładka klienta Gemini w Pythonie
plotting/
├── graphing.py # Renderer Matplotlib dla drzew myśli
README.md
Makefile
Backend Providentia Network jest zaprojektowany do iteracyjnych eksperymentów: aktualizuj prompty, dostosowuj heurystyki punktacji lub rozszerzaj format binarny według potrzeb. make run utrzymuje helper C++ w synchronizacji, abyś mógł skupić się na logice rozumowania. Miłego hakowania!