
Providence
Rete Providentia rifattorizzata.
Providentia Network è un backend basato su Django che orchestra il ragionamento multi-ramo con i modelli Gemini di Google, un co-processore nativo in C++ e visualizzazioni opzionali del grafo dei pensieri. Questo documento riassume l'architettura attuale e fornisce i comandi necessari per compilare ed eseguire il sistema in locale.
https://www.promptingguide.ai/techniques/tot
Yao et el. (2023) and Long (2023)
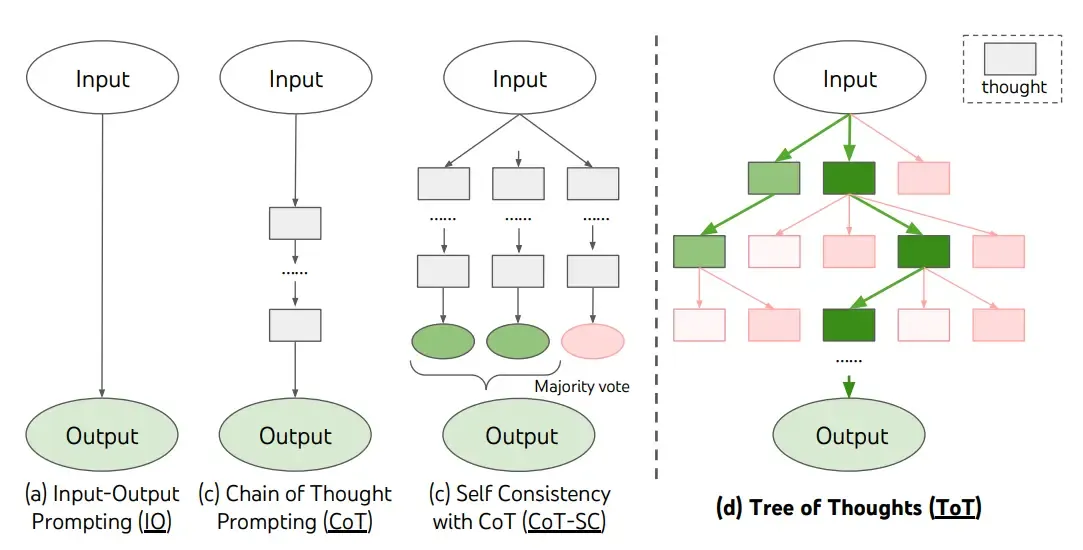
recently proposed Tree of Thoughts (ToT), a framework that generalizes over chain-of-thought prompting and encourages exploration over thoughts that serve as intermediate steps for general problem solving with language models.
ToT maintains a tree of thoughts, where thoughts represent coherent language sequences that serve as intermediate steps toward solving a problem. This approach enables an LM to self-evaluate the progress through intermediate thoughts made towards solving a problem through a deliberate reasoning process. The LM's ability to generate and evaluate thoughts is then combined with search algorithms (e.g., breadth-first search and depth-first search) to enable systematic exploration of thoughts with lookahead and backtracking.
Architettura del Sistema
Flusso dei Dati ad Alto Livello
Client -> /speech/simple_response (vista Django REST)
-> Python ThinkingManager (speech/context_manager/ThinkingManager.py)
-> Pensatore C++ "Kievan Rus" (speech/context_manager/Kievan Rus/*.cpp)
-> API Gemini (JSON su HTTPS)
-> Payload binario (stato + contesto + riepilogo)
-> Deserializzatore Python ed espansione dei rami
-> Grafo PNG opzionale (speech/context_manager/graphs/)
-> Testo della risposta Django
Componenti Principali
Endpoint Django REST (
speech/views.py)
Accetta un prompt utente, istanzia unThinkingManagere inoltra il testo dell'istruzione finale restituito dall'agente.Python Thinking Manager (
speech/context_manager/ThinkingManager.py)
Mantiene l'albero dei pensieri e applica le regole architetturali:- Avvia l'helper nativo C++ come sottoprocesso con il messaggio corrente, l'etichetta del ramo e i metadati dell'iterazione.
- Analizza la risposta binaria (1 byte di stato, 4 byte di lunghezza, payload UTF-8) e valida il JSON rispetto a
ContextStruct(Pydantic). - Registra per ogni ramo
probability_of_success,potential_scoreincrementale,possible_setbacksed etichette dei rami. - Garantisce almeno due esplorazioni di rami per livello e aggrega un punteggio potenziale cumulativo.
- Emette un albero testuale e opzionalmente genera un diagramma PNG (vedi sotto).
Pensatore C++ "Kievan Rus" (
speech/context_manager/Kievan Rus/)
Modularizzato in header/source per parsing degli argomenti, caricamento dell'ambiente, chiamate HTTP Gemini (libcurl), costruzione dei prompt e serializzazione binaria.- Legge la chiave API Gemini dall'ambiente di processo o da
.env. - Effettua due richieste Gemini: una per l'analisi strutturata, una per il riepilogo narrativo.
- Codifica il contesto strutturato e il riepilogo in un formato binario portatile consumato da Python.
- Il target Makefile
build-thinkerricompila il modulo (g++17,-lcurl) e viene eseguito automaticamente all'avvio del server.
- Legge la chiave API Gemini dall'ambiente di processo o da
Rendering del Grafo (
plotting/graphing.py)
Utilizza Matplotlib (backend Agg) per visualizzare l'albero dei pensieri finale. Ogni nodo include l'etichetta del ramo, il testo del piano avvolto, le probabilità, i delta di potenziale per passo, il potenziale cumulativo e le evidenziazioni per stati "finali" o "rimpianti". Le immagini vengono salvate inspeech/context_manager/graphs/.Agente Gemini (
speech/gemini/agent.py)
Wrapper leggero attorno al clientgenaidi Google. Il modulo C++ rispecchia questa funzionalità per il ragionamento critico in termini di latenza.
Semantica di Ramificazione e Punteggio
ThinkingManagermantiene la profondità dell'albero limitata (max_iterations = 8) ma garantisce che ogni nodo generi almeno due rami etichettati (es.Primary-A,Primary-B) a meno che non sia limitato dal numero massimo di iterazioni.- Ogni ramo porta:
probability_of_success— float limitato a[0.0, 1.0].potential_score— delta con segno aggiunto acumulative_potential.possible_setbacks— valutazione testuale del rischio incorporata nei log, nell'output della console e nelle visualizzazioni.
- I log vengono emessi per ogni creazione di ramo, valutazione numerica e passo di rendering del grafo per facilitare il debug.
Configurazione e Utilizzo
Prerequisiti
- Python 3 (si consiglia un ambiente virtualenv o Conda).
g++con supporto C++17 e header di sviluppo per libcurl.- Accesso a una chiave API Gemini (
GEMINI_API_KEY) inserita in.envo nell'ambiente di processo. - (Opzionale) Matplotlib per la generazione di grafi PNG; senza di esso il sistema registra un avviso e salta il plotting.
Creazione dell'Ambiente
make update # utilizza environment.yml tramite conda/micromamba
Override dei valori predefiniti:
make update CONDA_ENV=nome-ambiente
make update ENV_FILE=envs/dev.yml
make update CONDA=~/.local/bin/micromamba
Compilazione ed Esecuzione
make run # ricompila il pensatore C++ poi esegue `python manage.py runserver`
Compilazione standalone (se necessario):
make build-thinker # cd speech/context_manager/Kievan\ Rus && g++ ... -lcurl
Il server si aspetta .env nella directory principale del progetto a meno che non sia impostato KIEVAN_RUS_ENV_PATH.
Target Make Comuni
| Target | Descrizione |
|---|---|
make run |
Compila l'helper C++ e avvia il server di sviluppo Django |
make migrate |
Esegue le migrazioni (makemigrations + migrate) |
make prepare |
Crea l'ambiente Conda da environment.yml |
make update |
Aggiorna/crea l'ambiente Conda con pulizia |
make build-thinker |
Ricompila il modulo di ragionamento C++ |
make help |
Elenca i target disponibili (se definiti nel Makefile) |
Utilizzare PY=... per puntare a un interprete specifico, o sovrascrivere DJANGO_SETTINGS_MODULE secondo necessità.
Note di Configurazione
.envGEMINI_API_KEY=la-tua-chiave # impostazioni Django opzionali...KIEVAN_RUS_ENV_PATH(variabile d'ambiente) può sovrascrivere la posizione di.envper il processo C++.I grafi vengono scritti in
speech/context_manager/graphs/thought_graph_<id-radice>.png. Rimuovere la directory per pulire gli artefatti.
Suggerimenti per Test e Debug
- Il protocollo binario è rigoroso; risposte malformate da Gemini (es. campi
textmancanti) sollevano eccezioni chiare registrate sia dal layer Python che C++. - La creazione dei rami, i calcoli di probabilità e il rendering del grafo registrano tutti progressi dettagliati tramite prefissi
[ThinkingManager]. Osservare la console Django durante lo sviluppo per tracciare il flusso di ragionamento. - Se Matplotlib è assente, il sistema continua senza output PNG ma registra il fallimento dell'importazione.
Struttura del Repository (selezionata)
speech/
├── context_manager/
│ ├── ThinkingManager.py # Orchestratore Python
│ └── Kievan Rus/ # Pensatore nativo C++ (sorgenti modularizzati)
├── gemini/
│ └── agent.py # Wrapper client Python per Gemini
plotting/
├── graphing.py # Renderer Matplotlib per alberi dei pensieri
README.md
Makefile
Il backend di Providentia Network è progettato per la sperimentazione iterativa: aggiornate i prompt, regolate le euristiche di punteggio o estendete il formato binario secondo necessità. make run mantiene sincronizzato l'helper C++ in modo che possiate concentrarvi sulla logica di ragionamento. Buon hacking!