
Providence
Restructuration du réseau Providentia.
Providentia Network est un backend basé sur Django qui orchestre le raisonnement multi-branches à l'aide des modèles Gemini de Google, d'un coprocesseur natif en C++ et de visualisations optionnelles du graphe de pensée. Ce document résume l'architecture actuelle et fournit les commandes nécessaires pour compiler et exécuter le système localement.
https://www.promptingguide.ai/techniques/tot
Yao et al. (2023) et Long (2023)
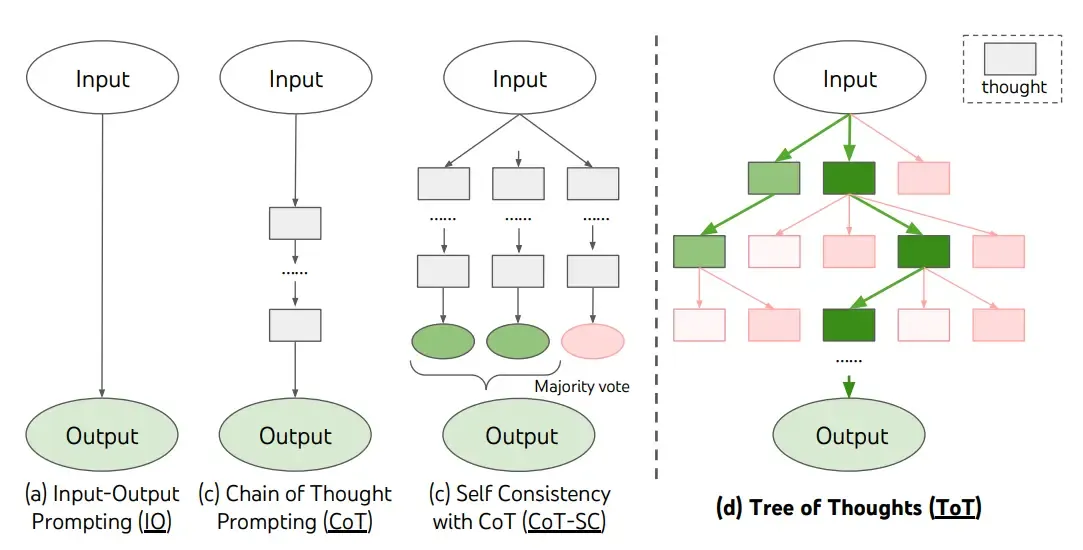
ont récemment proposé Tree of Thoughts (ToT), un cadre qui généralise les invites de chaîne de pensées et encourage l'exploration des pensées servant d'étapes intermédiaires pour la résolution générale de problèmes à l'aide de modèles linguistiques.
ToT maintient un arbre de pensées, où les pensées représentent des séquences linguistiques cohérentes qui servent d'étapes intermédiaires vers la résolution d'un problème. Cette approche permet à un modèle linguistique (LM) d'auto-évaluer les progrès réalisés grâce à des pensées intermédiaires visant à résoudre un problème par le biais d'un processus de raisonnement délibéré. La capacité du LM à générer et à évaluer des pensées est ensuite combinée à des algorithmes de recherche (par exemple, la recherche en largeur et la recherche en profondeur) pour permettre une exploration systématique des pensées avec anticipation et retour en arrière.
Architecture du système
Flux de données de haut niveau
Client -> /speech/simple_response (vue REST Django)
-> Python ThinkingManager (speech/context_manager/ThinkingManager.py)
-> Penseur C++ « Kievan Rus » (speech/context_manager/Kievan Rus/*.cpp)
-> API Gemini (JSON sur HTTPS)
-> Charge utile binaire (statut + contexte + résumé)
-> Désérialiseur Python et expansion des branches
-> Graphique PNG facultatif (speech/context_manager/graphs/)
-> Texte de réponse Django
Composants principaux
Point de terminaison Django REST (
speech/views.py)
Accepte une invite utilisateur, instancie unThinkingManageret transmet le texte d'instruction final renvoyé par l'agent.Gestionnaire de réflexion Python (
speech/context_manager/ThinkingManager.py)
Gère l'arbre de réflexion et applique les règles architecturales :- Lance l'assistant C++ natif en tant que sous-processus avec le message actuel, l'étiquette de branche et les métadonnées d'itération.
- Analyse la réponse binaire (statut de 1 octet, longueurs de 4 octets, charges utiles UTF-8) et valide le JSON par rapport à
ContextStruct(Pydantic). - Enregistre la
probability_of_successpar branche, lepotential_scoreincrémental, lespossible_setbackset les étiquettes de branche. - Garantit au moins deux explorations de branche par niveau et agrège un score potentiel cumulé.
- Génère un arbre textuel et affiche éventuellement un diagramme au format PNG (voir ci-dessous).
Penseur C++ « Kievan Rus » (
speech/context_manager/Kievan Rus/)
Modularisé en en-têtes/sources pour l'analyse des arguments, le chargement de l'environnement, les appels HTTP Gemini (libcurl), la construction de l'invite et la sérialisation binaire.- Lit la clé API Gemini à partir de l'environnement du processus ou du fichier
.env. - Émet deux requêtes Gemini : une pour l'analyse structurée, une pour le résumé narratif.
- Encode le contexte structuré et le résumé dans un format binaire portable exploitable par Python.
- La cible Makefile racine
build-thinkerrecompile le module (g++17,-lcurl) et est automatiquement enchaînée lors de l'exécution du serveur.
- Lit la clé API Gemini à partir de l'environnement du processus ou du fichier
Rendu graphique (
plotting/graphing.py)
Utilise Matplotlib (backend Agg) pour visualiser l'arbre de pensée final. Chaque nœud comprend une étiquette de branche, le texte du plan mis en forme, les probabilités, les deltas de potentiel par étape, le potentiel cumulé et des surlignages pour les états « finaux » ou « regrettés ». Les images sont enregistrées dansspeech/context_manager/graphs/.Agent Gemini (
speech/gemini/agent.py)
Enveloppe légère autour du clientgenaide Google. Le module C++ reproduit cette fonctionnalité pour le raisonnement où la latence est critique.
Sémantique des branches et de la notation
ThinkingManagerlimite la profondeur de l'arbre (max_iterations = 8) tout en garantissant que chaque nœud génère au moins deux branches étiquetées (par exemple,Primary-A,Primary-B) à moins d'être limité par le nombre maximal d'itérations.- Chaque branche comporte :
probability_of_success— nombre à virgule flottante limité à[0.0, 1.0].potential_score— delta signé ajouté àcumulative_potential.possible_setbacks— évaluation textuelle des risques intégrée dans les journaux, la sortie console et les visualisations.
- Des journaux sont générés à chaque création de branche, évaluation numérique et étape de rendu graphique afin de faciliter le débogage.
Configuration et utilisation
Prérequis
- Python 3 (un environnement virtualenv ou Conda est recommandé).
g++avec prise en charge de C++17 et en-têtes de développement pour libcurl.- Accès à une clé API Gemini (
GEMINI_API_KEY) placée dans.envou dans l'environnement du processus. - (Facultatif) Matplotlib pour la génération de graphiques PNG ; sans cela, le système enregistre un avertissement et ignore le traçage.
Création de l'environnement
make update # utilise environment.yml via conda/micromamba
Remplacer les valeurs par défaut :
make update CONDA_ENV=my-env-name
make update ENV_FILE=envs/dev.yml
make update CONDA=~/.local/bin/micromamba
Compilation et exécution
make run # recompile le thinker C++ puis exécute `python manage.py runserver`
Compilation autonome (si nécessaire) :
make build-thinker # cd speech/context_manager/Kievan\ Rus && g++ ... -lcurl
Le serveur s'attend à trouver .env à la racine du projet, sauf si KIEVAN_RUS_ENV_PATH est défini.
Cibles Make courantes
| Cible | Description |
|---|---|
make run |
Compiler l'assistant C++ et démarrer le serveur de développement Django |
make migrate |
Exécuter les migrations (makemigrations + migrate) |
make prepare |
Créer un environnement Conda à partir de environment.yml |
make update |
Mettre à jour/créer un environnement Conda avec élagage |
make build-thinker |
Recompiler le module de raisonnement C++ |
make help |
Lister les cibles disponibles (si définies dans Makefile) |
Utilisez PY=... pour pointer vers un interpréteur spécifique, ou remplacez DJANGO_SETTINGS_MODULE si nécessaire.
Remarques sur la configuration
.envGEMINI_API_KEY=votre-clé # paramètres Django facultatifs...KIEVAN_RUS_ENV_PATH(variable d'environnement) peut remplacer l'emplacement.envpour le processus C++.Les graphiques sont enregistrés dans
speech/context_manager/graphs/thought_graph_<root-id>.png. Supprimez le répertoire pour nettoyer les artefacts.
Conseils de test et de débogage
- Le protocole binaire est strict ; les réponses mal formées provenant de Gemini (par exemple, des champs
textmanquants) déclenchent des exceptions claires consignées à la fois par les couches Python et C++. - La création de branches, les calculs de probabilité et le rendu des graphes enregistrent tous une progression détaillée via les préfixes
[ThinkingManager]. Surveillez la console Django pendant le développement pour suivre le flux de raisonnement. - Si Matplotlib est manquant, le système continue sans sortie PNG mais consigne l'échec de l'importation.
Structure du référentiel (sélectionné)
speech/
├── context_manager/
│ ├── ThinkingManager.py # Orchestrateur Python
│ └── Kievan Rus/ # Penseur natif C++ (sources modularisées)
├── gemini/
│ └── agent.py # Wrapper client Python pour Gemini
plotting/
├── graphing.py # Rendu Matplotlib pour les arbres de pensée
README.md
Makefile
Le backend de Providentia Network est conçu pour l'expérimentation itérative : mettez à jour les invites, ajustez les heuristiques de notation ou étendez le format binaire selon vos besoins. La commande make run synchronise l'assistant C++ afin que vous puissiez vous concentrer sur la logique de raisonnement. Bon hacking !