
Providence
Red de Providentia refactorizada.
Providentia Network es un backend basado en Django que orquesta el razonamiento multi-rama con los modelos Gemini de Google, un co-procesador nativo en C++ y visualizaciones opcionales del grafo de pensamiento. Este documento resume la arquitectura actual y proporciona los comandos necesarios para construir y ejecutar el sistema localmente.
https://www.promptingguide.ai/techniques/tot
Yao et al. (2023) y Long (2023)
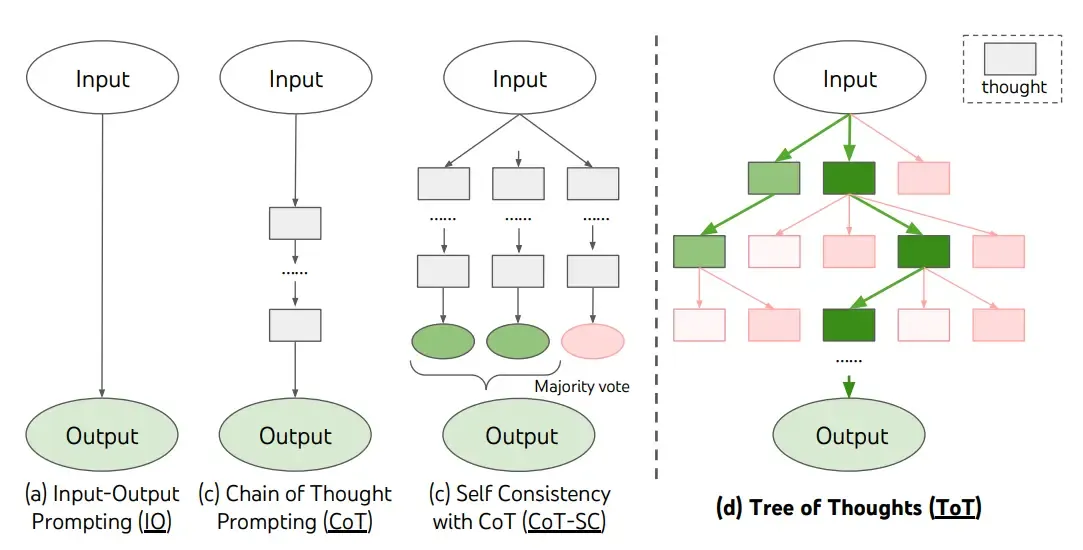
propusieron recientemente Tree of Thoughts (ToT), un marco que generaliza la indicación de cadena de pensamiento y fomenta la exploración de pensamientos que sirven como pasos intermedios para la resolución general de problemas con modelos de lenguaje.
ToT mantiene un árbol de pensamientos, donde los pensamientos representan secuencias de lenguaje coherentes que sirven como pasos intermedios hacia la resolución de un problema. Este enfoque permite que un LM se autoevalúe el progreso a través de pensamientos intermedios realizados para resolver un problema mediante un proceso de razonamiento deliberado. La capacidad del LM para generar y evaluar pensamientos se combina luego con algoritmos de búsqueda (por ejemplo, búsqueda en anchura y búsqueda en profundidad) para permitir la exploración sistemática de pensamientos con anticipación y retroceso.
Arquitectura del Sistema
Flujo de Datos de Alto Nivel
Cliente -> /speech/simple_response (vista Django REST)
-> Python ThinkingManager (speech/context_manager/ThinkingManager.py)
-> Pensador C++ "Kievan Rus" (speech/context_manager/Kievan Rus/*.cpp)
-> API Gemini (JSON sobre HTTPS)
-> Carga útil binaria (estado + contexto + resumen)
-> Deserializador Python y expansión de ramas
-> Grafo PNG opcional (speech/context_manager/graphs/)
-> Texto de respuesta Django
Componentes Principales
Endpoint REST Django (
speech/views.py)
Acepta una solicitud de usuario, instancia unThinkingManagery reenvía el texto de instrucción final devuelto por el agente.Python Thinking Manager (
speech/context_manager/ThinkingManager.py)
Mantiene el árbol de pensamiento y aplica reglas arquitectónicas:- Genera el helper nativo en C++ como un subproceso con el mensaje actual, la etiqueta de rama y los metadatos de iteración.
- Analiza la respuesta binaria (1 byte de estado, 4 bytes de longitud, cargas útiles UTF-8) y valida el JSON contra
ContextStruct(Pydantic). - Registra por rama
probability_of_success,potential_scoreincremental,possible_setbacksy etiquetas de rama. - Garantiza al menos dos exploraciones de rama por nivel y agrega una puntuación potencial acumulativa.
- Emite un árbol textual y opcionalmente renderiza un diagrama PNG (ver más abajo).
Pensador C++ "Kievan Rus" (
speech/context_manager/Kievan Rus/)
Modularizado en cabeceras/fuentes para análisis de argumentos, carga de entorno, llamadas HTTP a Gemini (libcurl), construcción de indicaciones y serialización binaria.- Lee la clave API de Gemini del entorno del proceso o de
.env. - Realiza dos solicitudes a Gemini: una para análisis estructurado, otra para resumen narrativo.
- Codifica el contexto estructurado y el resumen en un formato binario portátil consumido por Python.
- El objetivo
build-thinkerdel Makefile raíz recompila el módulo (g++17,-lcurl) y se encadena automáticamente al ejecutar el servidor.
- Lee la clave API de Gemini del entorno del proceso o de
Renderizado de Grafos (
plotting/graphing.py)
Utiliza Matplotlib (backend Agg) para visualizar el árbol de pensamiento final. Cada nodo incluye etiqueta de rama, texto de plan envuelto, probabilidades, deltas de potencial por paso, potencial acumulativo y resaltados para estados "final" o "arrepentido". Las imágenes se guardan enspeech/context_manager/graphs/.Agente Gemini (
speech/gemini/agent.py)
Envoltorio ligero alrededor del clientegenaide Google. El módulo C++ refleja esta funcionalidad para razonamiento crítico en latencia.
Semántica de Ramificación y Puntuación
ThinkingManagermantiene la profundidad del árbol limitada (max_iterations = 8) pero asegura que cada nodo genere al menos dos ramas etiquetadas (por ejemplo,Primary-A,Primary-B) a menos que esté limitado por el límite de iteración.- Cada rama lleva:
probability_of_success— flotante limitado a[0.0, 1.0].potential_score— delta con signo añadido acumulative_potential.possible_setbacks— evaluación de riesgos textual incrustada en registros, salida de consola y visualizaciones.
- Se emiten registros para cada generación de rama, evaluación numérica y paso de renderizado de grafo para facilitar la depuración.
Configuración y Uso
Requisitos Previos
- Python 3 (se recomienda un virtualenv o entorno Conda).
g++con soporte C++17 y cabeceras de desarrollo para libcurl.- Acceso a una clave API de Gemini (
GEMINI_API_KEY) colocada en.envo en el entorno del proceso. - (Opcional) Matplotlib para generación de grafos PNG; sin él, el sistema registra una advertencia y omite el trazado.
Creación del Entorno
make update # usa environment.yml mediante conda/micromamba
Anular valores predeterminados:
make update CONDA_ENV=my-env-name
make update ENV_FILE=envs/dev.yml
make update CONDA=~/.local/bin/micromamba
Construcción y Ejecución
make run # recompila el pensador C++ y luego ejecuta `python manage.py runserver`
Compilación independiente (si es necesario):
make build-thinker # cd speech/context_manager/Kievan\ Rus && g++ ... -lcurl
El servidor espera .env en la raíz del proyecto a menos que se establezca KIEVAN_RUS_ENV_PATH.
Objetivos Comunes de Make
| Objetivo | Descripción |
|---|---|
make run |
Construye el helper C++ e inicia el servidor de desarrollo Django |
make migrate |
Ejecuta migraciones (makemigrations + migrate) |
make prepare |
Crea el entorno Conda desde environment.yml |
make update |
Actualiza/crea el entorno Conda con poda |
make build-thinker |
Recompila el módulo de razonamiento C++ |
make help |
Lista los objetivos disponibles (si están definidos en Makefile) |
Use PY=... para apuntar a un intérprete específico, o anule DJANGO_SETTINGS_MODULE según sea necesario.
Notas de Configuración
.envGEMINI_API_KEY=tu-clave # configuraciones opcionales de Django...KIEVAN_RUS_ENV_PATH(variable de entorno) puede anular la ubicación de.envpara el proceso C++.Los grafos se escriben en
speech/context_manager/graphs/thought_graph_<id-raíz>.png. Elimine el directorio para limpiar artefactos.
Consejos de Prueba y Depuración
- El protocolo binario es estricto; las respuestas malformadas de Gemini (por ejemplo, campos
textfaltantes) generan excepciones claras registradas por las capas de Python y C++. - La creación de ramas, los cálculos de probabilidad y el renderizado de grafos registran el progreso detallado mediante prefijos
[ThinkingManager]. Observe la consola de Django durante el desarrollo para rastrear el flujo de razonamiento. - Si falta Matplotlib, el sistema continúa sin salida PNG pero registra el error de importación.
Estructura del Repositorio (seleccionada)
speech/
├── context_manager/
│ ├── ThinkingManager.py # Orquestador Python
│ └── Kievan Rus/ # Pensador nativo C++ (fuentes modularizadas)
├── gemini/
│ └── agent.py # Envoltorio del cliente Python para Gemini
plotting/
├── graphing.py # Renderizador Matplotlib para árboles de pensamiento
README.md
Makefile
El backend de Providentia Network está diseñado para experimentación iterativa: actualice las indicaciones, ajuste las heurísticas de puntuación o extienda el formato binario según sea necesario. make run mantiene el helper C++ sincronizado para que pueda centrarse en la lógica de razonamiento. ¡Feliz hacking!