
Providentia Network is a Django-based backend that orchestrates multi-branch reasoning with Google's Gemini models, a native C++ co-processor, and optional visualisations of the thought graph. This document summarises the current architecture and provides the commands needed to build and run the system locally.
https://www.promptingguide.ai/techniques/tot
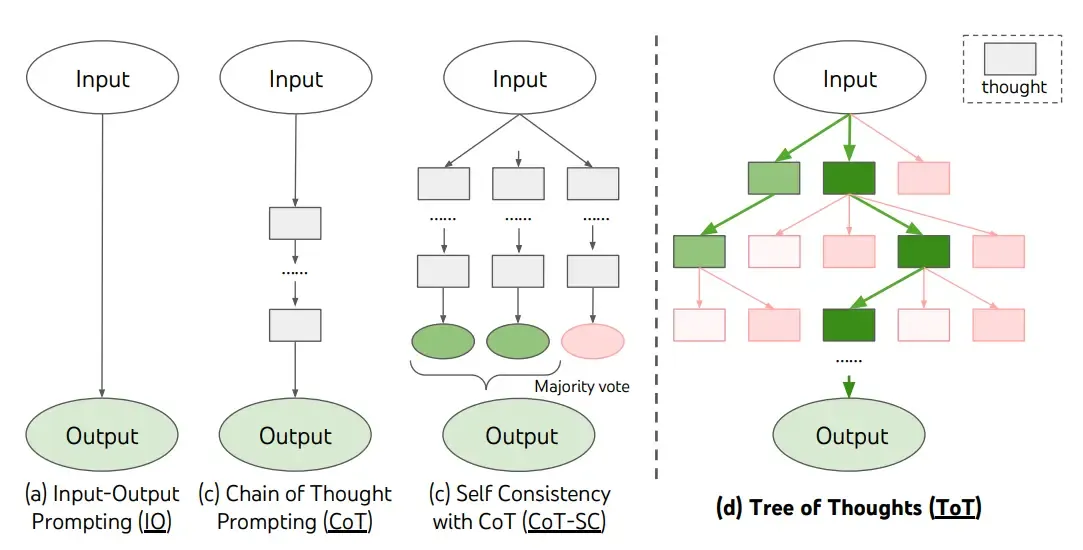
Yao et el. (2023) and Long (2023)
recently proposed Tree of Thoughts (ToT), a framework that generalizes over chain-of-thought prompting and encourages exploration over thoughts that serve as intermediate steps for general problem solving with language models.
ToT maintains a tree of thoughts, where thoughts represent coherent language sequences that serve as intermediate steps toward solving a problem. This approach enables an LM to self-evaluate the progress through intermediate thoughts made towards solving a problem through a deliberate reasoning process. The LM's ability to generate and evaluate thoughts is then combined with search algorithms (e.g., breadth-first search and depth-first search) to enable systematic exploration of thoughts with lookahead and backtracking.
System Architecture
High-Level Data Flow
Client -> /speech/simple_response (Django REST view)
-> Python ThinkingManager (speech/context_manager/ThinkingManager.py)
-> C++ “Kievan Rus” thinker (speech/context_manager/Kievan Rus/*.cpp)
-> Gemini API (JSON over HTTPS)
-> Binary payload (status + context + summary)
-> Python deserialiser & branch expansion
-> Optional PNG graph (speech/context_manager/graphs/)
-> Django response text
Core Components
Django REST Endpoint (
speech/views.py)
Accepts a user prompt, instantiates aThinkingManager, and forwards the final instruction text returned by the agent.Python Thinking Manager (
speech/context_manager/ThinkingManager.py)
Maintains the thought tree and enforces architectural rules:- Spawns the native C++ helper as a subprocess with the current message, branch label, and iteration metadata.
- Parses the binary response (1 byte status, 4 byte lengths, UTF-8 payloads) and validates the JSON against
ContextStruct(Pydantic). - Records per-branch
probability_of_success, incrementalpotential_score,possible_setbacks, and branch labels. - Guarantees at least two branch explorations per level and aggregates a cumulative potential score.
- Emits a textual tree and optionally renders a PNG diagram (see below).
C++ “Kievan Rus” Thinker (
speech/context_manager/Kievan Rus/)
Modularised into headers/sources for argument parsing, environment loading, Gemini HTTP calls (libcurl), prompt construction, and binary serialisation.- Reads the Gemini API key from the process environment or
.env. - Issues two Gemini requests: one for structured analysis, one for narrative summary.
- Encodes the structured context and summary into a portable binary format consumed by Python.
- The root Makefile target
build-thinkerrecompiles the module (g++17,-lcurl) and is chained automatically when running the server.
- Reads the Gemini API key from the process environment or
Graph Rendering (
plotting/graphing.py)
Uses Matplotlib (Agg backend) to visualise the final thought tree. Each node includes branch label, wrapped plan text, probabilities, per-step potential deltas, cumulative potential, and highlights for “final” or “regretted” states. Images land inspeech/context_manager/graphs/.Gemini Agent (
speech/gemini/agent.py)
Lightweight wrapper around Google’sgenaiclient. The C++ module mirrors this functionality for latency-critical reasoning.
Branching & Scoring Semantics
ThinkingManagerkeeps the tree depth bounded (max_iterations = 8) yet ensures every node spawns at least two labelled branches (e.g.,Primary-A,Primary-B) unless capped by the iteration limit.- Each branch carries:
probability_of_success— float clamped to[0.0, 1.0].potential_score— signed delta added tocumulative_potential.possible_setbacks— textual risk assessment embedded into logs, console output, and visualisations.
- Logs are emitted for every branch spawn, numeric evaluation, and graph rendering step to ease debugging.
Setup & Usage
Prerequisites
- Python 3 (a virtualenv or Conda environment is recommended).
g++with C++17 support and development headers for libcurl.- Access to a Gemini API key (
GEMINI_API_KEY) placed in.envor the process environment. - (Optional) Matplotlib for PNG graph generation; without it the system logs a warning and skips plotting.
Environment Creation
make update # uses environment.yml via conda/micromamba
Override defaults:
make update CONDA_ENV=my-env-name
make update ENV_FILE=envs/dev.yml
make update CONDA=~/.local/bin/micromamba
Building & Running
make run # recompiles the C++ thinker then runs `python manage.py runserver`
Standalone compilation (if needed):
make build-thinker # cd speech/context_manager/Kievan\ Rus && g++ ... -lcurl
The server expects .env at the project root unless KIEVAN_RUS_ENV_PATH is set.
Common Make Targets
| Target | Description |
|---|---|
make run |
Build C++ helper and start Django dev server |
make migrate |
Run migrations (makemigrations + migrate) |
make prepare |
Create Conda env from environment.yml |
make update |
Update/create Conda env with pruning |
make build-thinker |
Recompile the C++ reasoning module |
make help |
List available targets (if defined in Makefile) |
Use PY=... to point at a specific interpreter, or override DJANGO_SETTINGS_MODULE as needed.
Configuration Notes
.envGEMINI_API_KEY=your-key # optional Django settings...KIEVAN_RUS_ENV_PATH(environment variable) can override the.envlocation for the C++ process.Graphs are written to
speech/context_manager/graphs/thought_graph_<root-id>.png. Remove the directory to clean up artefacts.
Testing & Debugging Tips
- The binary protocol is strict; malformed responses from Gemini (e.g., missing
textfields) raise clear exceptions logged by both Python and C++ layers. - Branch creation, probability calculations, and graph rendering all log detailed progress via
[ThinkingManager]prefixes. Watch the Django console during development to track the reasoning flow. - If Matplotlib is missing, the system continues without PNG output but logs the import failure.
Repository Layout (selected)
speech/
├── context_manager/
│ ├── ThinkingManager.py # Python orchestrator
│ └── Kievan Rus/ # C++ native thinker (modularised sources)
├── gemini/
│ └── agent.py # Python Gemini client wrapper
plotting/
├── graphing.py # Matplotlib renderer for thought trees
README.md
Makefile
Providentia Network’s backend is designed for iterative experimentation: update the prompts, adjust scoring heuristics, or extend the binary format as needed. make run keeps the C++ helper in sync so you can focus on the reasoning logic. Happy hacking!