
Providence
Überarbeitetes Providentia-Netzwerk.
Providentia Network ist ein Django-basiertes Backend, das mehrzweigige Argumentation mit Googles Gemini-Modellen, einem nativen C++-Co-Prozessor und optionalen Visualisierungen des Gedankengraphen orchestriert. Dieses Dokument fasst die aktuelle Architektur zusammen und enthält die Befehle, die zum lokalen Bauen und Ausführen des Systems erforderlich sind.
https://www.promptingguide.ai/techniques/tot
Yao et al. (2023) und Long (2023)
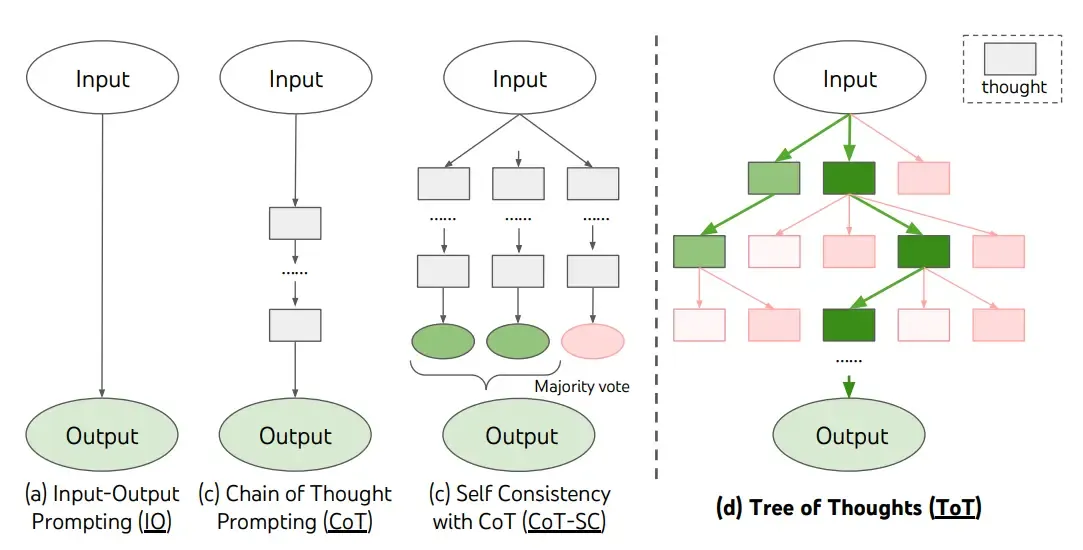
schlugen kürzlich Tree of Thoughts (ToT) vor, ein Framework, das Chain-of-Thought-Prompting verallgemeinert und die Erkundung von Gedanken fördert, die als Zwischenschritte zur allgemeinen Problemlösung mit Sprachmodellen dienen.
ToT verwaltet einen Baum von Gedanken, wobei Gedanken kohärente Sprachsequenzen darstellen, die als Zwischenschritte zur Lösung eines Problems dienen. Dieser Ansatz ermöglicht es einem LM, den Fortschritt durch Zwischengedanken zur Lösung eines Problems mittels eines bewussten Argumentationsprozesses selbst zu bewerten. Die Fähigkeit des LMs, Gedanken zu generieren und zu bewerten, wird dann mit Suchalgorithmen (z. B. Breitensuche und Tiefensuche) kombiniert, um eine systematische Erkundung von Gedanken mit Vorausschau und Rückverfolgung zu ermöglichen.
Systemarchitektur
Datenfluss auf hoher Ebene
Client -> /speech/simple_response (Django REST-View)
-> Python ThinkingManager (speech/context_manager/ThinkingManager.py)
-> C++ „Kievan Rus“-Denker (speech/context_manager/Kievan Rus/*.cpp)
-> Gemini-API (JSON über HTTPS)
-> Binärer Payload (Status + Kontext + Zusammenfassung)
-> Python-Deserialisierer & Zweigexpansion
-> Optionaler PNG-Graph (speech/context_manager/graphs/)
-> Django-Antworttext
Kernkomponenten
Django REST-Endpunkt (
speech/views.py)
Nimmt eine Benutzereingabe entgegen, instanziiert einenThinkingManagerund leitet den endgültigen Anweisungstext weiter, der vom Agenten zurückgegeben wird.Python Thinking Manager (
speech/context_manager/ThinkingManager.py)
Verwaltet den Gedankenbaum und setzt Architekturregeln durch:- Startet den nativen C++-Helfer als Unterprozess mit der aktuellen Nachricht, Zweigbezeichnung und Iterationsmetadaten.
- Analysiert die binäre Antwort (1 Byte Status, 4 Byte Längen, UTF-8-Payloads) und validiert das JSON gegen
ContextStruct(Pydantic). - Zeichnet pro Zweig
probability_of_success, inkrementellenpotential_score,possible_setbacksund Zweigbezeichnungen auf. - Garantiert mindestens zwei Zweigexplorationen pro Ebene und aggregiert einen kumulativen Potenzialwert.
- Gibt einen textuellen Baum aus und rendert optional ein PNG-Diagramm (siehe unten).
C++ „Kievan Rus“-Denker (
speech/context_manager/Kievan Rus/)
Modularisiert in Header/Quellen für Argument-Parsing, Umgebungsladen, Gemini-HTTP-Aufrufe (libcurl), Prompt-Konstruktion und binäre Serialisierung.- Liest den Gemini-API-Schlüssel aus der Prozessumgebung oder
.env. - Führt zwei Gemini-Anfragen durch: eine für strukturierte Analyse, eine für narrative Zusammenfassung.
- Kodiert den strukturierten Kontext und die Zusammenfassung in ein portables Binärformat, das von Python konsumiert wird.
- Das Makefile-Ziel
build-thinkerkompiliert das Modul neu (g++17,-lcurl) und wird beim Ausführen des Servers automatisch verkettet.
- Liest den Gemini-API-Schlüssel aus der Prozessumgebung oder
Graph-Rendering (
plotting/graphing.py)
Verwendet Matplotlib (Agg-Backend), um den endgültigen Gedankenbaum zu visualisieren. Jeder Knoten enthält Zweigbezeichnung, umbrochenen Plantext, Wahrscheinlichkeiten, schrittweise Potenzialdeltas, kumulatives Potenzial und Hervorhebungen für „finale“ oder „bereute“ Zustände. Bilder landen inspeech/context_manager/graphs/.Gemini-Agent (
speech/gemini/agent.py)
Leichter Wrapper um Googlesgenai-Client. Das C++-Modul spiegelt diese Funktionalität für latenzkritische Argumentation wider.
Verzweigungs- & Bewertungssemantik
ThinkingManagerhält die Baumtiefe begrenzt (max_iterations = 8), stellt aber sicher, dass jeder Knoten mindestens zwei benannte Zweige erzeugt (z. B.Primary-A,Primary-B), es sei denn, das Iterationslimit ist erreicht.- Jeder Zweig trägt:
probability_of_success— Gleitkommazahl begrenzt auf[0.0, 1.0].potential_score— vorzeichenbehaftetes Delta, das zucumulative_potentialaddiert wird.possible_setbacks— textuelle Risikobewertung, eingebettet in Logs, Konsolenausgabe und Visualisierungen.
- Logs werden für jede Zweigerzeugung, numerische Bewertung und jeden Graph-Rendering-Schritt ausgegeben, um das Debugging zu erleichtern.
Einrichtung & Verwendung
Voraussetzungen
- Python 3 (eine virtualenv- oder Conda-Umgebung wird empfohlen).
g++mit C++17-Unterstützung und Entwicklungs-Headern für libcurl.- Zugang zu einem Gemini-API-Schlüssel (
GEMINI_API_KEY), platziert in.envoder der Prozessumgebung. - (Optional) Matplotlib für die PNG-Graph-Generierung; ohne es protokolliert das System eine Warnung und überspringt die Darstellung.
Umgebungserstellung
make update # verwendet environment.yml via conda/micromamba
Standardwerte überschreiben:
make update CONDA_ENV=mein-env-name
make update ENV_FILE=envs/dev.yml
make update CONDA=~/.local/bin/micromamba
Bauen & Ausführen
make run # kompiliert den C++-Denker neu und führt dann `python manage.py runserver` aus
Eigenständige Kompilierung (falls erforderlich):
make build-thinker # cd speech/context_manager/Kievan\ Rus && g++ ... -lcurl
Der Server erwartet .env im Projektstammverzeichnis, es sei denn, KIEVAN_RUS_ENV_PATH ist gesetzt.
Häufige Make-Ziele
| Ziel | Beschreibung |
|---|---|
make run |
C++-Helfer bauen und Django-Entwicklungsserver starten |
make migrate |
Migrationen ausführen (makemigrations + migrate) |
make prepare |
Conda-Umgebung aus environment.yml erstellen |
make update |
Conda-Umgebung aktualisieren/erstellen mit Bereinigung |
make build-thinker |
C++-Argumentationsmodul neu kompilieren |
make help |
Verfügbare Ziele auflisten (falls in Makefile definiert) |
Verwenden Sie PY=..., um auf einen bestimmten Interpreter zu verweisen, oder überschreiben Sie DJANGO_SETTINGS_MODULE nach Bedarf.
Konfigurationshinweise
.envGEMINI_API_KEY=Ihr-Schlüssel # optionale Django-Einstellungen...KIEVAN_RUS_ENV_PATH(Umgebungsvariable) kann den.env-Speicherort für den C++-Prozess überschreiben.Graphen werden nach
speech/context_manager/graphs/thought_graph_<root-id>.pnggeschrieben. Entfernen Sie das Verzeichnis, um Artefakte zu bereinigen.
Test- & Debugging-Tipps
- Das binäre Protokoll ist streng; fehlerhafte Antworten von Gemini (z. B. fehlende
text-Felder) lösen klare Ausnahmen aus, die von beiden Schichten (Python und C++) protokolliert werden. - Zweigerstellung, Wahrscheinlichkeitsberechnungen und Graph-Rendering protokollieren alle detaillierte Fortschritte mit
[ThinkingManager]-Präfixen. Beobachten Sie die Django-Konsole während der Entwicklung, um den Argumentationsfluss zu verfolgen. - Wenn Matplotlib fehlt, läuft das System ohne PNG-Ausgabe weiter, protokolliert aber den Importfehler.
Repository-Struktur (Auswahl)
speech/
├── context_manager/
│ ├── ThinkingManager.py # Python-Orchestrator
│ └── Kievan Rus/ # C++-nativer Denker (modularisierte Quellen)
├── gemini/
│ └── agent.py # Python-Gemini-Client-Wrapper
plotting/
├── graphing.py # Matplotlib-Renderer für Gedankenbäume
README.md
Makefile
Das Backend von Providentia Network ist für iteratives Experimentieren ausgelegt: Aktualisieren Sie die Prompts, passen Sie Bewertungsheuristiken an oder erweitern Sie das Binärformat nach Bedarf. make run hält den C++-Helfer synchron, sodass Sie sich auf die Argumentationslogik konzentrieren können. Viel Spaß beim Hacken!