
Providence
Reestruturação da Rede Providentia.
A Rede Providentia é um backend baseado em Django que orquestra o raciocínio multirramificado com os modelos Gemini do Google, um coprocessador nativo em C++ e visualizações opcionais do gráfico de pensamentos. Este documento resume a arquitetura atual e fornece os comandos necessários para compilar e executar o sistema localmente.
https://www.promptingguide.ai/techniques/tot
Yao et al. (2023) e Long (2023)
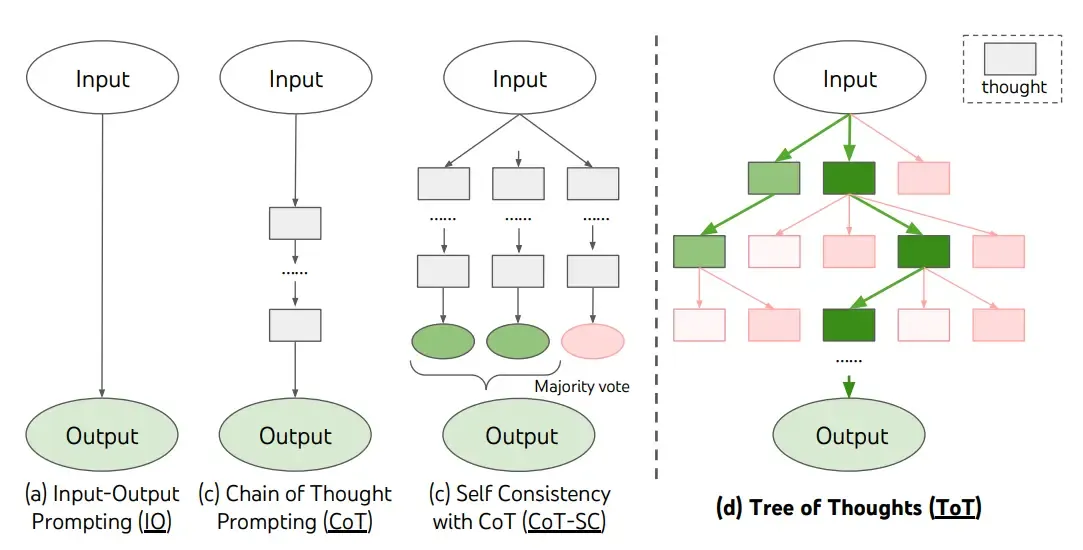
propuseram recentemente o Tree of Thoughts (ToT), uma estrutura que generaliza o prompt de cadeia de pensamentos e incentiva a exploração de pensamentos que servem como etapas intermediárias para a resolução geral de problemas com modelos de linguagem.
O ToT mantém uma árvore de pensamentos, na qual os pensamentos representam sequências linguísticas coerentes que servem como etapas intermediárias para a resolução de um problema. Essa abordagem permite que um LM autoavalie o progresso por meio de pensamentos intermediários direcionados à resolução de um problema, através de um processo de raciocínio deliberado. A capacidade do LM de gerar e avaliar pensamentos é então combinada com algoritmos de busca (por exemplo, busca em largura e busca em profundidade) para permitir a exploração sistemática de pensamentos com antecipação e retrocesso.
Arquitetura do Sistema
Fluxo de Dados de Alto Nível
Cliente -> /speech/simple_response (visualização REST do Django)
-> Python ThinkingManager (speech/context_manager/ThinkingManager.py)
-> Pensador “Kievan Rus” em C++ (speech/context_manager/Kievan Rus/*.cpp)
-> API Gemini (JSON sobre HTTPS)
-> Carga binária (status + contexto + resumo)
-> Deserializador Python e expansão de ramificação
-> Gráfico PNG opcional (speech/context_manager/graphs/)
-> Texto de resposta do Django
Componentes principais
Ponto de extremidade REST do Django (
speech/views.py)
Aceita um prompt do usuário, instancia umThinkingManagere encaminha o texto da instrução final retornado pelo agente.Gerenciador de pensamento em Python (
speech/context_manager/ThinkingManager.py)
Mantém a árvore de pensamento e aplica regras arquitetônicas:- Inicia o auxiliar nativo em C++ como um subprocesso com a mensagem atual, o rótulo da ramificação e os metadados de iteração.
- Analisa a resposta binária (status de 1 byte, comprimentos de 4 bytes, cargas úteis UTF-8) e valida o JSON contra
ContextStruct(Pydantic). - Registra por ramificação
probability_of_success,potential_scoreincremental,possible_setbackse rótulos de ramificação. - Garante pelo menos duas explorações de ramificação por nível e agrega uma pontuação potencial cumulativa.
- Emite uma árvore textual e, opcionalmente, renderiza um diagrama em PNG (veja abaixo).
Pensador “Kievan Rus” em C++ (
speech/context_manager/Kievan Rus/)
Modularizado em cabeçalhos/fontes para análise de argumentos, carregamento de ambiente, chamadas HTTP do Gemini (libcurl), construção de prompts e serialização binária.- Lê a chave da API do Gemini a partir do ambiente do processo ou do
.env. - Emite duas solicitações ao Gemini: uma para análise estruturada e outra para resumo narrativo.
- Codifica o contexto estruturado e o resumo em um formato binário portátil consumido pelo Python.
- O alvo Makefile raiz
build-thinkerrecompila o módulo (g++17,-lcurl) e é acionado automaticamente ao executar o servidor.
- Lê a chave da API do Gemini a partir do ambiente do processo ou do
Renderização de gráficos (
plotting/graphing.py)
Utiliza o Matplotlib (backend Agg) para visualizar a árvore de pensamento final. Cada nó inclui rótulo de ramificação, texto do plano encapsulado, probabilidades, deltas de potencial por etapa, potencial cumulativo e destaques para estados “finais” ou “lamentados”. As imagens são salvas emspeech/context_manager/graphs/.Agente Gemini (
speech/gemini/agent.py)
Wrapper leve em torno do clientegenaido Google. O módulo C++ espelha essa funcionalidade para raciocínio em que a latência é crítica.
Semântica de ramificação e pontuação
- O
ThinkingManagermantém a profundidade da árvore limitada (max_iterations = 8), mas garante que cada nó gere pelo menos dois ramos rotulados (por exemplo,Primary-A,Primary-B), a menos que seja limitado pelo limite de iterações. - Cada ramificação contém:
probability_of_success— float restrito a[0.0, 1.0].potential_score— delta assinado adicionado acumulative_potential.possible_setbacks— avaliação de risco textual incorporada em logs, saída de console e visualizações.
- Logs são emitidos para cada geração de ramificação, avaliação numérica e etapa de renderização de gráficos para facilitar a depuração.
Configuração e uso
Pré-requisitos
- Python 3 (recomenda-se um ambiente virtualenv ou Conda).
g++com suporte a C++17 e cabeçalhos de desenvolvimento para libcurl.- Acesso a uma chave da API Gemini (
GEMINI_API_KEY) colocada em.envou no ambiente do processo. - (Opcional) Matplotlib para geração de gráficos PNG; sem ele, o sistema registra um aviso e ignora o plotagem.
Criação do ambiente
make update # usa environment.yml via conda/micromamba
Substituir padrões:
make update CONDA_ENV=my-env-name
make update ENV_FILE=envs/dev.yml
make update CONDA=~/.local/bin/micromamba
Compilação e execução
make run # recompila o thinker em C++ e, em seguida, executa `python manage.py runserver`
Compilação independente (se necessário):
make build-thinker # cd speech/context_manager/Kievan\ Rus && g++ ... -lcurl
O servidor espera encontrar .env na raiz do projeto, a menos que KIEVAN_RUS_ENV_PATH esteja definido.
Alvos comuns do Make
| Alvo | Descrição |
|---|---|
make run |
Compila o auxiliar C++ e inicia o servidor de desenvolvimento Django |
make migrate |
Executa migrações (makemigrations + migrate) |
make prepare |
Cria o ambiente Conda a partir de environment.yml |
make update |
Atualiza/cria o ambiente Conda com poda |
make build-thinker |
Recompilar o módulo de raciocínio em C++ |
make help |
Listar alvos disponíveis (se definidos no Makefile) |
Use PY=... para indicar um interpretador específico ou substitua DJANGO_SETTINGS_MODULE conforme necessário.
Notas de configuração
.envGEMINI_API_KEY=sua-chave # configurações opcionais do Django...KIEVAN_RUS_ENV_PATH(variável de ambiente) pode substituir o local do.envpara o processo C++.Os gráficos são gravados em
speech/context_manager/graphs/thought_graph_<root-id>.png. Remova o diretório para limpar artefatos.
Dicas de teste e depuração
- O protocolo binário é rigoroso; respostas malformadas do Gemini (por exemplo, campos
textausentes) geram exceções claras registradas tanto pela camada Python quanto pela camada C++. - A criação de ramificações, os cálculos de probabilidade e a renderização de gráficos registram o progresso detalhado por meio de prefixos
[ThinkingManager]. Observe o console do Django durante o desenvolvimento para acompanhar o fluxo de raciocínio. - Se o Matplotlib estiver ausente, o sistema continua sem saída em PNG, mas registra a falha na importação.
Estrutura do repositório (selecionado)
speech/
├── context_manager/
│ ├── ThinkingManager.py # Orquestrador Python
│ └── Kievan Rus/ # Pensador nativo em C++ (códigos modularizados)
├── gemini/
│ └── agent.py # Wrapper do cliente Gemini em Python
plotting/
├── graphing.py # Renderizador Matplotlib para árvores de pensamento
README.md
Makefile
O backend da Providentia Network foi projetado para experimentação iterativa: atualize os prompts, ajuste as heurísticas de pontuação ou amplie o formato binário conforme necessário. make run mantém o auxiliar C++ sincronizado para que você possa se concentrar na lógica de raciocínio. Boa programação!